Word2Vec : Skip-gram with Negative Sampling
Introduction
Lorsque j’ai voulu faire un algorithme de recommandation, je suis tombé sur Word2Vec et plus particulièrement la version SGNS (Skip-GRAM negativ sampling) et au lieu d’utiliser simplement un modèle tout fait (gensim) que je comprenais à peine, je me suis dis pourquoi pas tout recoder from scratch pour vraiment comprendre ce qu’il y a derrière. Le Word2Vec originel consiste à faire de l’embedding de mots pour capturer la sémantique (voir si les mots ont des sens proches). Ce modèle peut être étendu à d’autres domaines comme la recommandation de musqiue par exemple, en consdiérant une playlist comme une phrase et une musique comme un mot. Ici, on va cependant coder le W2V orignel et s’occuper de mots, pas de musique.
Le challenge était d’autant plus intéréssant que je n’ai trouvé aucune implémentation from scratch du SGNS (seulement un code utilisant pytorch ce qui facilite pas mal de choses…). Je me suis donc basé majoritairement sur le papier du SGNS et des ébauches d’internet.
Modèle
Les Débuts
Ici on s’intéresse à Word2Vec Skip-gram: on part d’un mot central et on veut prédire le “contexte”: les mots adjacents. (W2V CBOW fait l’inverse: prédit center avec le contexte).
Word2Vec est un petit réseau de neurones, mais qu’on ne va pas utiliser pour classifier: on va entraîner notre modèle à prédire la probabilité qu’un mot soit proche d’un autre, mais le résultat final correspond à la matrice des poids d’entrée qui sera la matrice d’embedding. C’est là la subtilité !
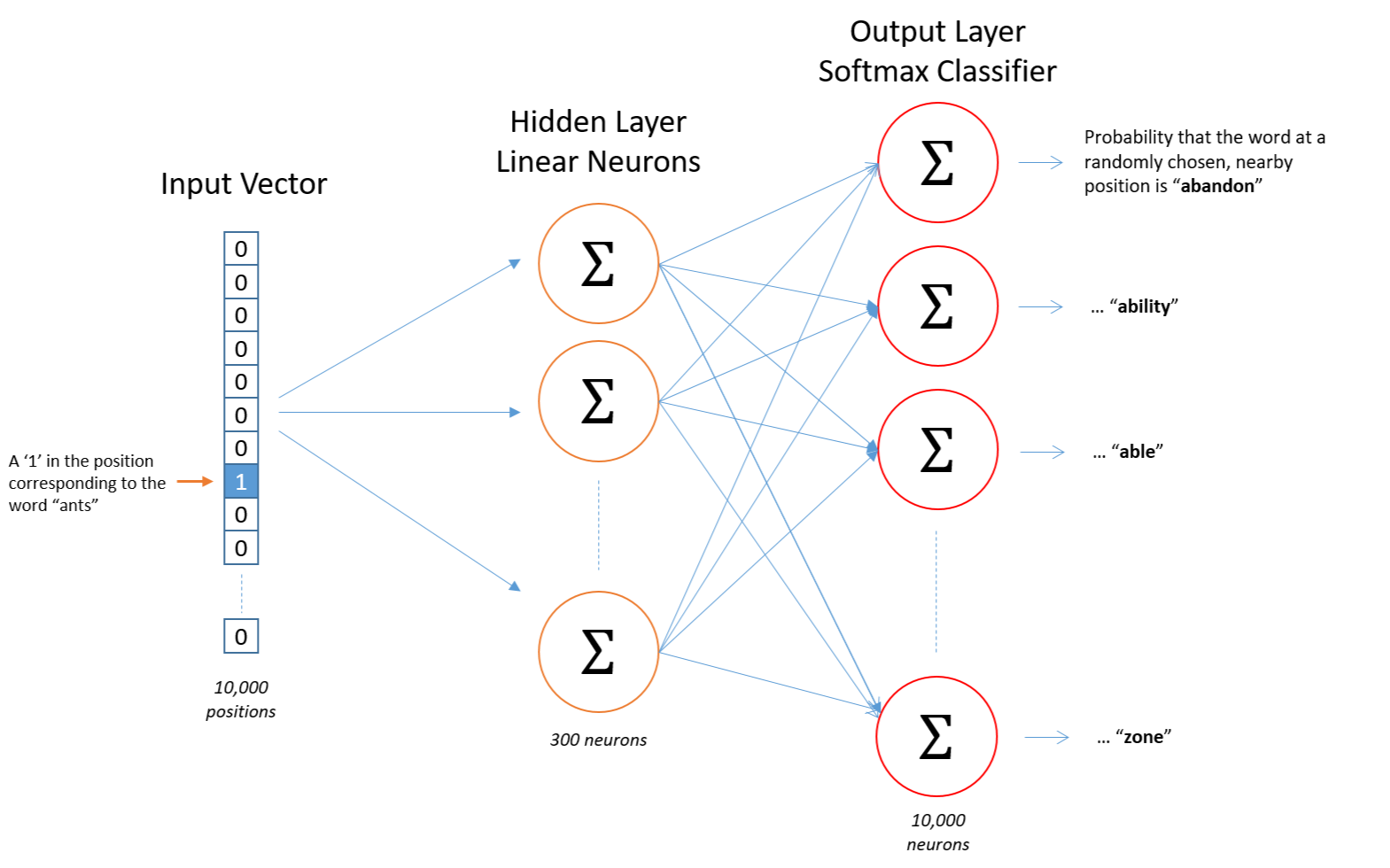
La photo montre l’idée du Skip-Gram, c’est loin de l’implémentation réelle, mais on y fait un petit détour pour mieux comprendre. On considère un vocabulaire de 10k mots et on va faire des embeddings de dimensions 300 (on réduit de 10k à 300).
On prend un mot qu’on considère comme un vecteur (on fait de l’embedding), il passe par une première couche qui capture les informations importantes (on passe ici par exemple de dim=10000 à dim=300) des mots. On va appeler la matrice de poids liée à cette couche $W_{in}$ pour input embedding matrix. Cette matrice contient l’information des mots quand ils jouent le rôle de “centre” (on utilisera $W_{in}$ comme matrice d’embdding). C’et donc cette matrice en particulier qui va nous intéréssé et par ailleurs, on voit qu’on fait de l’embedding: on a réduit la dimension et extrait des informations importantes.
Ensuite, on fait passer nos vecteurs dans la dernière couche à laquelle on associe la matrice de poids $W_{out}$, la output embedding matrix. Puis on fait un softmax sur le vecteur final pour ressortir des probabilités. Celui-ci aura comme dimension 10k: la taille du vocabulaire et chaque composante correspond à la proba que le mot i soit proche de “ants” dans notre exemple.
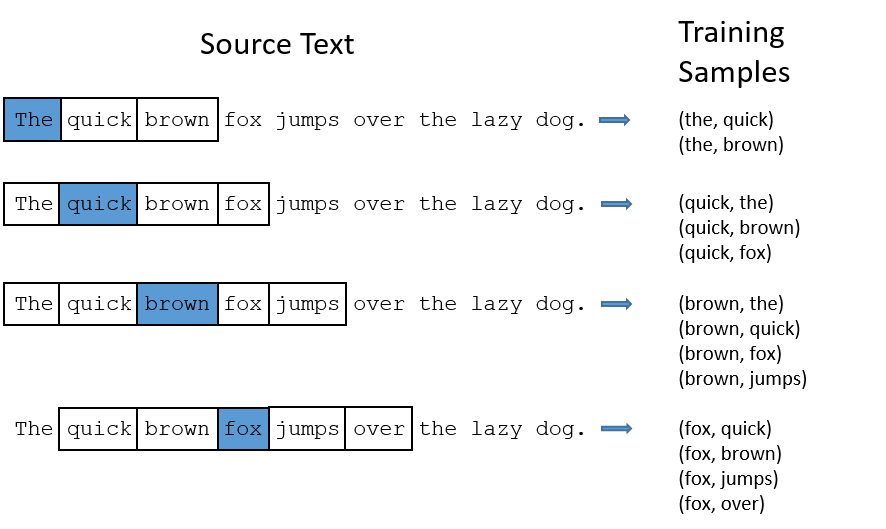
Dans nos phrases, la fenêtre des mots considérés comme du contexte est un paramètre: on peut dire au modèle de ne regarder que 2 mots autour du mot central comme 10 mots autour. Cette fenêtre est en pratique aléatoire (uniformément entre 1 et la valeur donnée comme paramètre). Ça veut dire qu’un mot peut avoir 1, 2, …, jusqu’à la fenêtre maximale (R) de mots autour de lui. On prends jusqu’à R mots à gauche et R mots à droite, en respectant : les bords de la phrase, la segmentation en phrases (on ne traverse pas un « . », « ? », « ! »).
Cette fenêtre dynamique est importante : elle réduit le sur-apprentissage sur les mots proches immédiats et elle introduit un bruit contrôlé qui stabilise SGNS. C’est aussi ce qu’utilise Mikolov dans l’implémentation originale. Voici un exemple d’extraction de donnée d’entraînement à partir d’une phrase pour mieux comprendre (center,context):
La Loss qui va nous intérésser correspond donc à une somme sur l’opposé des logs de ces probabilités:
\[p(w_O \mid w_{I}) = \frac{\exp({v'_{w_O}}^\top v_{w_I})} {\sum_{w=1}^{W} \exp({v'_w}^\top v_{w_I})}\]I pour le mot centre, O pour le mot contexte et W le nombre de mots dans le vocabulaire.
On voit que à chaque terme de la somme, on va devoir sommer sur tout le vocabulaire…
On remarque que le réseau de neurones est gigantesque (on a 10k neurones en sortie comme la taille du vocab ici est 10k) et donc que chaque matrice aurait 3 millions de composantes (poids)! On voit aussi que la loss sera compliqué à calculer comme on doit à chaque fois sommer sur tout le vocabulaire plusieurs fois.
Le problème principal est le coût de calcul : pour chaque paire (centre, contexte), il faut sommer sur tout le vocabulaire dans le softmax et mettre à jour un grand nombre de poids. C’est trop lent pour de gros vocabulaires.
C’est pourquoi, on utilise du negativ sampling (SGNS pour skip-gram negativ sampling).
Negativ sampling
Au lieu de modifier toute notre matrice de poids à chaque training sample ce que l’on fait pour l’instant (la loss dépend de tous les mots du vocabulaire), on va seulement update une petite partie mais intelligemment.
En prenant les exemples de training samples de ci-dessus et en considérant comme mot central “fox”, des positivs samples seraient “brown”, “jumps” tandis que des negativ samples seraient “horse”, “table”.
Les negativs samples vont être des mots qui ne sont pas dans le contexte du mot central et qu’on va choisir aléatoirement dans le vocabulaire, tandis que les positivs samples sont des mots dont on veut que le mot central soit proche.
Notre loss devient:
\[\mathcal{L}(c,o,\{n_i\}_{i=1}^K) = - \log \sigma(\mathbf{v}_o^\top \mathbf{v}_c) -\sum_{i=1}^K \log \sigma(-\mathbf{v}_{n_i}^\top \mathbf{v}_c).\]On a les $n_{i}$ pour les mots negativ samples, $v_{c}$ pour le vecteur centre et $v_{o}$ pour le vecteur positif (context)
Il faut faire attention au fait que $v_{c}$ vit dans la matrice $W_{in}$ et $v_{o}$ vit dans la matrice $W_{out}$
On n’est passé d’une loss générale à une loss spécifique pour chaque training sample (1 training sample = 1 pair (center,context) ) qu’on cherche à minimiser. Ici K est le nombre de negativ samples qu’on décide de mettre pour chaque sample dans l’entrainement (on prend généralement K entre 5 et 20, papier de Word2Vec), c’est un hyper-paramètre du modèle, il est fixe durant tout l’entrainement.
On voit qu’on ne somme plus sur tout le vocabulaire ce qui allège considérablement le temps de calcul, car on ne va pas mettre à jours tous les poids à sample. On va à la place mettre K+2 vecteurs à jour (center, context et les negativ samples).
Afin de tirer aléatoirement ces negativ samples, on va utiliser une distribution unigramme modifiée (paramètre 3/4) avec pour le mot $w_i$,
\[P(w_i) = \min(\frac{ f(w_i)^{3/4} }{ \sum_{j=0}^{|Vocab|} f(w_j)^{3/4} },1)\]L’exposant 0.75 sert à lisser la distribution : il diminue un peu le poids des mots ultra fréquents (the, of, …) tout en gardant une probabilité plus élevée que les mots rares.
On peut montrer que SGNS est proche de la factorisation d’une matrice de PMI (Pointwise Mutual Information) entre mots et contextes, ce qui explique pourquoi les vecteurs capturent bien des relations sémantiques.
Subsampling
Un autre élement ajouté au model de base de W2V est le subsampling. Dans l’exemple de la langue anglaise, on a des mots beaucoup plus fréquents que d’autres: the,is,and,… Ces mots beaucoup plus fréquents nuisent au modèle si on les laisse tels quels. On aurait 12000 samples pour the comme centre et 100 samples pour king et le modèle ne verrait que the et is comme mots.
C’est pourquoi, on utilise du subsampling: on va enlever une grande partie des paires pour équilibrer le dataset. Plus un mot est fréquent, plus on enlevera des paires (mot fréquent,context). Ceci est fait grâce à la formule:
\[P_{\text{keep}}(w) = \left( \sqrt{\frac{f(w)}{t}} + 1 \right) \cdot \frac{t}{f(w)}\]où w correspond à un mot, f(w) à sa fréquence dans le corpus et t est un paramètre du modèle (en général t=1e-5). Plus t est petit et moins on garde les mots et les mots rares sont quasi toujours garder.
Traitement
On va passer maintenant à un peu plus de pratique et coder.
On va d’abord débuter par le traitement des données. Dans mon cas, mon dataset correspond à wikitext2 qui est suffisant. C’est un petit dataset par rapport à ce qui est disponible, mais ça permet de faire tourner en moins de 5 min les modèles sur de petites machines et le modèle arrive à extraire de bonnes relations entre les mots (Word2vec est ultra scalable). Notre donnée d’entrainement correspond à des paires (center,context) qui vont être issues de phrases qu’on va délimiter par des ., des ? et des !.
Le code est en libre accès sur mon github, je vous conseille vivement de l’avoir en parallèle de ce post pour y voir plus clair.
text = corpus.lower()
text = re.sub(r"[^a-z0-9.,!?;:'\-()\s]", " ", text)
tokens = re.findall(r"[a-z0-9]+(?:'[a-z0-9]+)?|[.,!?;:()\-]", text)Ensuite, on va créer notre vocabulaire et on va associer des mots à des id, car on manipule des nombres dans les vecteurs. C’est ce que fait la fonction tokenisation qui renvoie aussi le compte des mots (count) dans le corpus et leur fréquence relative (f_relg).
count va nous servir à faire la distribution pour tirer les négatives samples (build_noise) et les fréquences relatives (f_relg) servent pour le subsampling (filtre_s).
On utilise ensuite ces données pour créer nos training samples ou paires dans les fonctions pair (qui utilise une fenêtre de contexte dynamique) et pairs
Modèle Word2Vec SGNS from scratch
Modèle
On va d’abord faire un peu de maths: Ce qui nous intérèsse, c’est le gradient de la loss, car c’est lui qui donne la direction afin de minimiser la loss. Pour cela, on va déjà calculer les dérivées partielles par rapport à chaque composante de la loss:
\[\frac{\partial \mathcal{L}}{\partial \mathbf{v}_c} = (\sigma(\mathbf{v}_o^\top \mathbf{v}_c)-1)\mathbf{v}_o + \sum_{i=1}^K \sigma(\mathbf{v}_{n_i}^\top \mathbf{v}_c)\mathbf{v}_{n_i}.\] \[\frac{\partial \mathcal{L}}{\partial \mathbf{v}_o} = (\sigma(\mathbf{v}_o^\top \mathbf{v}_c)-1)\mathbf{v}_c .\] \[\frac{\partial \mathcal{L}}{\partial \mathbf{v}_{n_i}} = \sigma(\mathbf{v}_{n_i}^\top \mathbf{v}_c)\mathbf{v}_c, \qquad i=1,\dots,K.\]Désormais, on va pouvoir mettre à jour les matrices $W_in$ et $W_out$ au fur et à mesure des samples. C’et ce qu’on observe dans train de la classe Word2vec:
neg_ids = self.sample_negatives(self.K, rng)
neg_vecs = self.W_out[neg_ids]
pos = np.dot(v_c, v_o)
pos = np.clip(pos, -10, 10) #we clip to keep convergence, 10 -10 is suffisant for the sigmoid
neg = neg_vecs.dot(v_c)
neg = np.clip(neg, -10, 10) #we clip to keep convergence, 10 -10 is suffisant for the sigmoidut
sig_pos = sigmoid(pos)
sig_neg = sigmoid(neg)
grad_c = (sig_pos - 1) * v_o + np.sum(sig_neg[:, None] * neg_vecs, axis=0)
grad_o = (sig_pos - 1) * v_c
grad_negs = sig_neg[:, None] * v_c[None, :]
self.W_in[center_id] -= lr_t * grad_c
self.W_out[context_id] -= lr_t * grad_o
np.add.at(self.W_out, neg_ids, -lr_t * grad_negs)On suit bien la direction du gradient (pondéré par le learning rate) et on modifie les 2 matrices. Le np.add.at permet de prendre en compte les doublons d’indice: Les mots fréquents ont plus de chances d’être tirés pour les negativ sample et ce n’est pas étonnant d’avoir 2 fois le même mot comme negativ sample. Pour ne pas sous mettre à jour ces mots-ci, on ajoute les gradients pour ne pas qu’il s’écrase les uns les autres, mais s’additionnent.
Stabilisation du modèle
On utilise un learning décroissant, car il va empêcher les normes de diverger (ici on a pas fait de régularisation de vecteur).
De plus, il faut noter que l’on shuffle les pairs, donc tout nos données d’entrainement pour que le modèle traite équitablement chaque paire (pas que la paire (king,charles) n’entraîne aucune mise à jour, car elle se retrouve à la fin où le learning rate est à sa valeur minimale).
Rapidité sur le choix des negativ samples
Mikolov a eu l’idée de créer une table de distribution au lieu de faire un np.random.choice par exemple qui serait en O(|Vocabulaire|). On va créer une table immense où chaque position correspond à un mot. Le nombre de fois que ce mot est dans la table est proportionnel à sa probabilité d’être tiré en tant que negativ sample. On passe alors à du O(1).
Comparaison et métrique
On peut calculer une loss moyenne sur un sous-ensemble de mots et voir à chaque epoch si elle baisse, mais je me suis fondé sur des cosine similarity et les 20-plus proches voisins des mots king ou football pour voir si mon modèle était pertinent ou non. Voici la formule de la cosine similarity:
\[\cos(u, v) = \frac{u \cdot v}{\|u\|_2 \, \|v\|_2}\]Résultats
Voici les paramètres que j’ai utilisé pour les résultats que je vais vous présentez. Le modèle est enregistré sur mon github et le code est fonctionnel pour que vous faisiez le votre (je n’ai pas fais d’optimisation d’hyper paramètres). Je normalise aussi $W_{in}$ avant de trouver les k plus proches voisins.
- window_size_max = 3
- embed_dim = 300
- negatives = 5
- lr_initial = 0.025
- epochs = 5
- t = 1e-3
Top 10 voisins pour ‘king’:
| Mot | Score |
|---|---|
| henry | 0.7735 |
| william | 0.7537 |
| george | 0.7510 |
| james | 0.7244 |
| son | 0.7180 |
| john | 0.7088 |
| edward | 0.7079 |
| richard | 0.7008 |
| charles | 0.6987 |
| michael | 0.6868 |
Analogie [king - man + woman] vs queen (cosine): 0.6920
king $= [ 0.2738726 , -0.1502892 , -0.11983082 , -0.0713472 , -0.07030658] $
queen $= [ 0.15040387 , -0.00734318 , -0.02329289 , -0.09677064 , -0.10576637]$
Top 10 voisins pour ‘football’:
| Mot | Score |
|---|---|
| championship | 0.8472 |
| cup | 0.8328 |
| rugby | 0.8279 |
| tag | 0.8254 |
| baseball | 0.8085 |
| conference | 0.8075 |
| premier | 0.8009 |
| league | 0.8007 |
| fa | 0.7895 |
| liverpool | 0.7843 |
| finals | 0.7826 |
On observe bien que notre modèle a appris des sémantiques et les résulats sont vraiment correctes par rapport à des modèles optimisés comme ceux de gensim. La cosine similarity pour l’analogie King vs Queen étant de 0.61 pour Gensim, notre modèle a vraisemblablement mieux compris le lien entre king et queen. Gensim renvoie néanmoins des résultats un peu plus pertinent:
Top 10 voisins pour ‘football’ de Gensim:
| Mot | Score |
|---|---|
| basketball | 0.8902 |
| athletic | 0.8893 |
| rugby | 0.8882 |
| baseball | 0.8821 |
| hockey | 0.8784 |
| yeovil | 0.8662 |
| wheelchair | 0.8638 |
| conference | 0.8585 |
| coaches | 0.8581 |
| aston | 0.8513 |
On a des similiarity plus élevées sur certains sport, mais on voit bien que notre modèle est performant et récupère de la sémantique !!!!!