Regression Ridge
Introduction
Commençons au commencement: la régréssion OLS (ordinary least square) qui est la régréssion linéaire de base et aussi le classique des cours de statistiques. Pour rappel, la formule de close de l’estimateur est $\hat{\beta} = (X^{\top} X)^{-1} X^{\top} y$
$ X \in \mathbb{R}^{n \times p}$ est la matrice des variables explicatives (matrice de design), $y \in \mathbb{R}^{n}$ est le vecteur des observations, $\hat{\beta} \in \mathbb{R}^{p}$ est l’estimateur des paramètres du modèle, $n$ est le nombre d’observations,$p$ est le nombre de paramètres (variables explicatives, intercept inclus).
On rappelle les hypothèses:
\(y = X\beta + \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0, \sigma^2 I_n).\) Ce qui est intéréssant pour y voir plus clair dans les soucis que pose la OLS, c’est la décomposition en valeurs singulières (SVD). Avec celle-ci, on a directement que
\[\operatorname{Var}\!\left(\hat{\beta}_{\mathrm{OLS}}\right) = \sigma^{2} V \operatorname{diag}\!\left(\frac{1}{\lambda_1},\dots,\frac{1}{\lambda_i}\right) V^{\top}\]où $\lambda_i = \gamma_{i}^2$ avec $\gamma_i$ les valeurs singulières de $X$. et en se plaçant dans la base propre, on s’intéresse aux coefficient $ \frac{1}{\lambda_{i}}$. On voit que si un des élements est nul, donc si on a de la colinéarité, la variance liée à ce paramètre diverge (dans la direction propre associée) et fausse le modèle. De plus la variance estimée des erreurs dépend de n et p. \(\hat{\sigma}^2 = \frac{1}{n - p} \left\lVert y - X\hat{\beta} \right\rVert^2\)
Si p>n, $X^{\top} X$ n’est plus inversible et l’estimateur n’est plus unique. Si p=n, donc on a plus de degré de liberté, on ne peut plus estimée $\hat{\sigma}^2$ qui devient indéfinie et par conséquent on ne peut plus estimer $\sigma$, le modèle devient non identifiable (le modèle n’aurait alors plus de sens). Enfin si la matrice $X^{\top}X$ est mal conditionné, notre modèle devient instable et donc pas utilisable.
C’est pourquoi, on va utiliser Ridge qui va nous permettre de palier à ces deux soucis: réduire la dimensionalité et en même temps réduire les paramètres inutiles.
Ridge
Modèle brut
Ridge n’est pas gratuit, on va certes baisser la variance de nos estimateurs, mais on va aussi augmenter leur biais.
L’idée de la méthode Ridge, c’est d’ajouter une pénalisation $L^2$ associée à un hyper-paramètre $\alpha \ge 0$ (“shrinkage”: on rétrécit les plages de valeurs que peuvent prendre les paramètres estimés) à notre problème d’optimisation:
\[\hat{\beta}_{\text{ridge}} = \arg\min_{\beta} \left( \| y - X\beta \|_2^2 + \alpha \| \beta \|_2^2 \right)\]Cela permet de bien poser le problème peut importe la valeur de $p$ ou $n$ ou encore si on a des variables colinéaires. On force un bon conditionnement, $X^{\top}X + \alpha I$ inversible et on borne la variance.
Compréhension du modèle
Approche bayésienne
Déjà, on va se demander pourquoi on ajoute un terme $\alpha || \beta ||_2^2$. On peut le comprendre en utilisant l’approche bayésienne des statistiques, en fait le ridge va même être équivalent à une MAP (maximum à postériori):
On commence par utiliser le théorème de Bayes et appliquer le log. $\log P(\theta \mid X, y) = \log P(X, y \mid \theta) + \log P(\theta) - \log P(X, y)$ Avec $X,y$ les observations et $\theta$ le paramètre.
Ici, on veut maximiser $\log P(\theta \mid X, y)$ ou minimiser le coût $J(\theta)=-\log P(\theta \mid X, y)$, donc pour ça on maximise $\log P(X, y \mid \theta) + \log P(\theta)$.
On retrouve nos 2 termes de la fonction de coût: $-\log P(\theta)$ pour la régularisation et $-\log P(X, y \mid \theta)$ pour le terme de l’OLS.
En fait, en allant plus loin on peut montrer que $P(X, y \mid \theta) = \mathcal{N}(y \mid X\theta, \sigma_1^2), \quad P(\theta) = \mathcal{N}(\theta \mid 0, \sigma_2^2)$ correspond à la fonction de coût posé au paragraphe précédent.
Ce qui est fondamental et très intéréssant, c’est qu’en faisant du ridge, on suppose que $\theta$ ou pour nous ici $\beta \sim \mathcal{N}(0, \tau^2 I)$.
On suppose donc que notre modèle correspond à plein de petits effets qui s’ajoutent ensemble et ainsi ridge = prior gaussien. De là, on comprend les propriété de Ridge et ces particularités (par exemple, la pénalisation dépend uniquement de la norme, pas de la direction parce que une gaussienne est invariante par rotation!).
Fin de l’interlude statistique
Approche du coût
Pour voir tout les avantages proprement du ridge, on revient aux valeurs singulières de $X$.
On a comme solution unique du problème: $\hat{\beta} = (X^{\top} X+\alpha I)^{-1} X^{\top}y$ Cette fois l’estimateur est biaisé:
\[\mathbb{E}[\hat{\beta}] = (X^{\top} X+\alpha I)^{-1} X^{\top} X\, \beta\]et en se plaçant dans la base propre, $\mathbb{E}[\hat{\beta_i}] = \frac{\gamma_{i}^2}{\gamma_{i}^2 + \alpha} \beta_i $, donc un biais $\operatorname{Bias}(\hat{\beta}_i)= -\frac{\alpha}{\gamma_i^2 + \alpha}\,\beta_i$ (*)
On voit que le biais est non nul tant que $\alpha >0$ et de plus il est borné (en valeur absolue) par “le coefficient réel” avec la borne atteinte quand $\alpha \to +\infty$. C’est logique, parce que si $\alpha = \infty$, on écrase les coefficients estimés qui valent 0.
De même avec la variance:
\[\operatorname{Var}(\hat{\beta}) = \sigma^2 (X^\top X + \alpha I)^{-1} X^\top X (X^\top X + \alpha I)^{-1}\]et en passant à la SVD:
\[\operatorname{Var}(\hat{\beta}_i) = \sigma^2 \frac{\gamma_i^2}{(\gamma_i^2+\alpha)^2}\]On voit qu’on a clairement diminué la variance par rapport au modèle OLS et qu’elle est décroissante avec $\alpha$. De plus, quand $\gamma_i = 0$, la variance et l’espérance sont nulles et alors le coefficient est nul avec une probabilité de 1.
Il faut en pratique prendre quelques précautions avec la Ridge:
- On normalise les $x_i$ qui deviennent alors centrés et réduits de telle sorte à ce que la pénalisation soit équitable et afin d’éviter que les observations à fortes variances aient trop d’influence (sans normalisation, elle serait beaucoup moins pénalisée, car $\gamma_i$ serait grand et on aurait un facteur de shrinkage (*) proche de 1).
- On centre alors la variable cible y pour ne pas pénaliser l’intercept. On enlève ainsi l’intercept, car les $x_i$ étant centrés, l’intercept vaut la moyenne de y. Ainsi, aucune pénalisation sera appliqué à l’intercept En effet, celui-ci ne représente pas une association entre la variable cible et une variable explicative.
Implémentation du modèle
Place à l’implémentation from scratch.
def __init__(self,X):
self.X = X
self.mu_X = self.X.mean(axis=0)
self.sigma_X = self.X.std(axis=0, ddof=0)
self.Xc = (self.X - self.mu_X) / self.sigma_X
self.U, self.d, self.Vt = np.linalg.svd(self.Xc, full_matrices=False)
self.V = self.Vt.T
self.Xct = self.Xc.TLe modèle est défini à partir des observations, donc X et on utilisera la target Y dans fit
Tout d’abord on normalise X comme on l’a vu plus tôt. C’est une étape qu’on aurait pu faire dans fit, mais comme je voulais principalement faire une fonction qui teste plusieurs valeurs de $\alpha$ (cf ci-dessous), je l’ai gardé dans init pour économiser des calculs.
Ensuite, ce qui va nous aider à ne pas recalculer l’inverse d’une matrice dépendant de $\alpha$ non explicite, on va utilser la SVD qui nous donne une formule close connaissant V et U. Le paramètre full_matrices=False permet de calculer la SVD économique (on garde les valeurs singulières non nulles), ce qui évite de manipuler des dimensions inutiles lorsque n != p, sans modifier les directions pertinentes.
La 2e méthode importante est fit:
def fit(self, y,alpha):
self.mu_y = y.mean()
yc = y - self.mu_y
shrink = self.d / (self.d**2 + alpha)
beta_s = self.Vt.T @ (shrink * (self.U.T @ yc))
self.coef = beta_s / self.sigma_X
self.intercept = self.mu_y - self.mu_X @ self.coef
return self.coef, self.interceptTout d’abord, on centre y, puis on calcule l’estimation de notre modèle standardisé à l’aide de notre formule close simplifiée avec la SVD. On revient ensuite à notre vrai modèle, la standardisation étant bijective avec un écart type non nul:
\[y_s = X_s \beta_s, y_s = y-\mu_y, X_s = \frac{X-\mu_X}{\sigma_X}, y = \frac{X}{\sigma_X} \beta_s + \mu_y - \mu_{X}^{\top}\beta_s\]On notera qu’on s’est occupé de l’intercept à part pour qu’il ne soit pas pénalisé. Maintenant on peut désormais prédire. (la fonction predict est sur le github, comme tout le code présenté et nécéssaire à ce post)
Prédiction
Ici, on va compare la OLS au Ridge sur des données représentées par 2 points qu’on va bruiter pour voir que ridge est bien plus robuste et les coefficients sont plus stables, en effet la variance est diminuée.
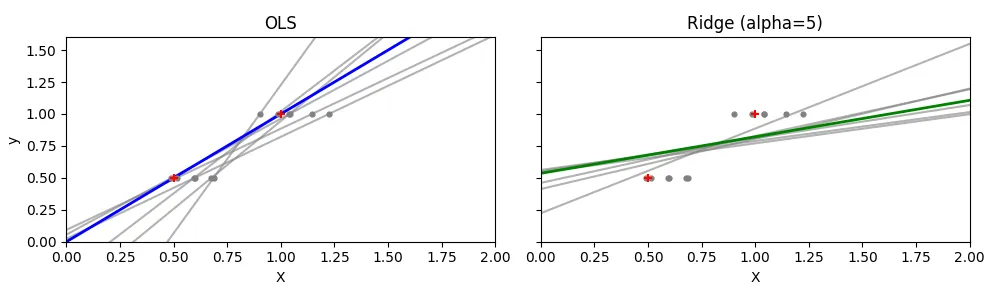
On a donc crées 6 réalisations bruitées et 1 réalisation non bruitée du jeu de donnée. On a fit un modèle (OLS et Ridge) pour chaque observation. C’est ce qu’on voit sur les graphes ci-dessus: les droites prédites avec Ridge sont beaucoup plus proche les 1 des autres. Ici l’OLS overfit totalement (le modèle apprend le bruit) et c’est ce qu’on évite avec Ridge. Certes on perd dans le biais, mais on gagne en généralisation. La courbe verte et la bleue correspondent à l’observation non bruitée.
Scikit-learn ne propose pas directement la standardisation des données (il faut utiliser StandardScaler() en plus), mais notre modèle from scratch le fait dès qu’un modèle est initialisé (ridge(X)). On aurait aussi pu mettre la standardisation dans le fit, mais ayant fait une fonciton qui teste une plage de valeurs de alpha, cela évite de refaire la standardisation à chaque fit.
X_train = np.array([[0.5], [1.0]])
y_train = np.array([0.5, 1.0])
alpha = 5
X_plot = np.array([[0],[2]])
noises = 0.1 * np.random.normal(size=(6,) + X_train.shape)
for eps in noises:
this_X = X_train + eps
rd = ridge(this_X)
rd.fit(y_train, alpha)La question maintenant, c’est comment choisir $\alpha$. Dans notre comparaison d’avant, j’ai choisi $\alpha$ à l’oeil, mais $\alpha$ est un hyper-paramètre et on cherche le $\alpha$ optimal. Optimal par rapport à quoi? Par rapport à l’erreur de prédiction, donc ici aux résidus ou RSS ou RSSE ou une autre métrique quantifiant l’erreur. Pour ça, on peut utiliser 2 méthodes: on teste le modèle sur un set de test et on cherche le alpha qui minimise l’erreur sur ce set de test ou on fait de la cross-validation (si les données sont trop peu nombreuses).
Ici, on va tester sur le dataset housing_california où d’ailleurs l’OLS marche relativement bien outre des features corrélées. On split le dataset en 2:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)On trouve d’abord le alpha optimal à l’aide de la fonction find dans la classe ridge:
def rss(self, X_t, y_t):
y_pred = X_t @ self.coef + self.intercept
return np.sum((y_t - y_pred)**2)
def find(self, mx, n, X_val, y_val, y_train):
J=np.logspace(-4, np.log10(mx), n)
rssm=np.inf
self.rm=[]
self.v=[]
self.best_alpha=None
for alpha in J:
self.fit(y_train, alpha)
b=self.rss(X_val, y_val)
self.rm.append(b)
self.v.append(alpha)
if b<rssm:
rssm=b
self.best_alpha=alpha
return self.best_alpha,rssmIci, on donne une valeur $\alpha_max$ et find fait des modèles pour chaque $\alpha$ dans J où J est une discrétisation logarithmique de l’intervalle $[10e-4,\alpha_{max}]$. On cherche ensuite le $\alpha$ qui minimise la RSS et on compare avec la RSS en OLS.
Results:
- Best alpha : 168.3
- RSS Ridge : 2780.0
- RSS OLS : 2792.2
On observe bien une amélioration grâce au Ridge (pour une meilleure stabilité de la RSS et des résultats, une cross-validation aurait été mieux). Enfin on plot le graphe de la RSS (la métrique d’évaluation que j’ai choisis) en fonction de alpha.
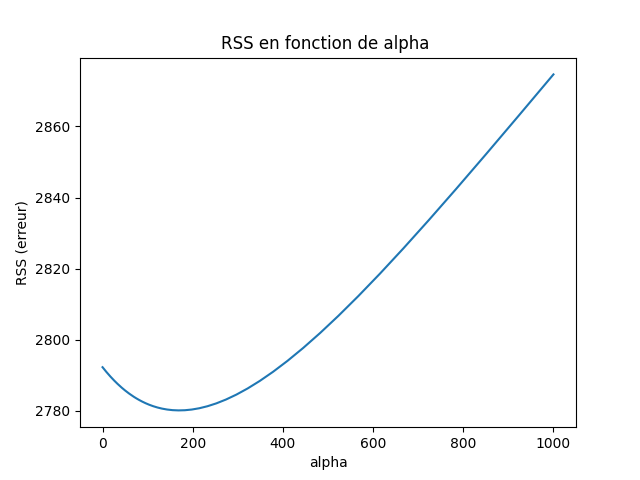
On voit bien qu’il faut un juste millieux entre OLS instable et généralisation trop brutale, c’est ce que propose l’hyper-paramètre $\alpha$ ou ici $\alpha$ pour s’accomoder à python.