Regression LASSO
Introduction
Après avoir étudié Ridge en profondeur en va s’occuper de son alter ego: Lasso ou Least absolute shrinkage and selection operator. On a vu que Ridge tirait les coefficients vers 0, mais ne les annulaient pas. Lasso, lui permet d’éliminer des variables ou autrement dit de sélectionner les variables pour ne garder que des variables significatives.
Lasso est un modèle de régularisation et certains coefficients vaudront donc exactement 0.
LASSO
Modèle
Au lieu d’avoir une régularisation L2 comme dans Ridge, LASSO propose une régularisation L1:
\(\hat{\beta}_{\text{lasso}} = \arg\min_{\beta} \left( \frac{\| y - X\beta \|_2^2}{2} + \lambda\| \beta \|_1 \right)\) où $X \in \mathbb{R}^{n\times p}$ et $\beta \in \mathbb{R}^{p}$
Cette fois on ne pourra pas résoudre ce problème avec une forme explicite comme pour Ridge ou OSL ou du moins pas directement.
On peut ajouter un facteur $\frac{1}{n}$ que l’on a aussi omis dans le problème ridge qui permet d’avoir un $\lambda$ indépendant de la taille du dataset ce qui permet des comparaisons.
Ici néanmoins, on ne le met pas afin d’avoir une expression simple et on ne compte pas faire des comparaisons entre dataset. Cela signifie que $\lambda$ varie en fonction de la taille du dataset.
Approche de résolution
Plusieurs algorithmes plus ou moins performants existent, mais nous choisissons ici d’utiliser le coordinate descent basique.
Scikit utilise le coordinate decent safe screening gap qui utilise des concepts de convexité, dualité et autres qui vont trop loin pour le projet ici présent (cf mon prochain post).
Ici nous allons donc utiliser le coordinate descent tout court. L’idée c’est que même si le LASSO n’admet pas de solution explicite, si on se place en 1 dimension, on obtient une formule explicite.
On va donc optimiser non pas globalement, mais par variable et itérer sur les variables.
Commençons par dériver la solution explicite pour une coordonnée $\beta_{j}$ où $j \in {1,\dots,p}$. On remarque le problème se réécrit alors
\[\hat{\beta}_{j} = \arg\min_{\beta_{j}} \left( \frac{\| y - X_{-j}\beta_{-j} - \beta_{j}x_{j} \|_2^2}{2} + \lambda |\beta_{j}| \right) =\arg\min_{\beta_{j}}(\rho(\beta_j))\]Avec $X=(x_1,\dots,x_p)$, $\quad X_{-j}=(x_1,\dots,x_{j-1},0,x_{j+1},\dots,x_p)$ et $\beta_{-j}$ le vecteur $\beta$ privé de $\beta_j$. On note donc que $X_{-j}\beta_{-j}$ est une somme de vecteurs et en notant $r_{j}=y - X_{-j}\beta_{-j}$, $\quad \mathbf{r_j}$ est indépendant de $\mathbf{\beta_j}$.
Pour être bien au clair sur les notations, on a $x_j= (X_{1,j},\dots,X_{n,j})$
La valeur absolue n’étant pas différentiable en 0, on utilise la notion de sous gradient pour calculer le gradient de $\rho$, puis la condition de fermat pour trouver la formule explicite de $\beta_j$.
\[\partial |x| = \begin{cases} \{-1\} & \text{si } x < 0 \\ \{1\} & \text{si } x > 0 \\ [-1,1] & \text{si } x = 0 \end{cases}\]C’est cet intervalle $[-1,1]$ qui permet aux coefficients de valoir strictement 0 pour certaines valeurs de $\lambda$ ce que l’on va comprendre dans un instant.
En dérivant donc $\rho$, on obtient \(\partial \rho(\beta_j) = \begin{cases} \{-\lambda+\beta_j \|x_j\|_2^2- x_{j} ^ \top r_{j}\} & \text{si } \beta_j < 0 \\ \{\lambda +\beta_j \|x_j\|_2^2- x_{j}^\top r_{j}\} & \text{si } \beta_j > 0 \\ [-\lambda-x_{j}^\top r_{j},\lambda-x_{j}^\top r_{j}] & \text{si } \beta_j = 0 \end{cases}\)
On utilise enfin la condition de fermat pour conclure que:
\[\beta_j \|x_j\|_2^2 = \begin{cases} \lambda+x_{j}^\top r_{j} & \text{si } x_{j}^\top r_{j} < -\lambda \\ -\lambda+x_{j}^\top r_{j} & \text{si } x_{j}^\top r_{j} >\lambda \\ 0 & \text{si } \lambda \ge |x_{j}^\top r_{j}| \end{cases}\]Le troisième cas est celui qui donne des conditions pour avoir un coefficient valant purement 0 en fonction de la valeur de $\lambda$ par rapport aux données.
En divisant par $|x_j|_2^2$ et en compactant l’expression, on obtient: \(\beta_j=\operatorname{sign}(x_{j}^\top r_{j})\frac{\max(0,|x_{j}^\top r_{j}|-\lambda)}{\|x_j\|_2^2}\)
Il ne faut pas oublier que le résidu $r_j$ dépend des coefficients $\beta_{-j}$. Par conséquent, la mise à jour de $\beta_j$ s’effectue en considérant les autres coefficients comme fixés. L’algorithme de coordinate descent consiste donc en des passes successives sur les coordonnées, chaque coefficient étant mis à jour à tour de rôle.
On utilise ici un critère de convergence simple basé sur un nombre maximal d’itérations, correspondant à un nombre fixé de passes sur l’ensemble des $p$ coefficients (par exemple $m$ passes).
Bien que la convergence du coordinate descent soit garantie pour le problème du LASSO, l’utilisation de critères plus fins tels que les conditions KKT ou les méthodes de safe screening gap n’est pas retenue ici.
Résolution numérique
On s’attaque maintenant à la partie code:
def __init__(self,X):
self.X = X
self.mu_X = self.X.mean(axis=0)
self.sigma_X = self.X.std(axis=0, ddof=0)
self.sigma_X[self.sigma_X == 0] = 1.0
self.Xc = (self.X - self.mu_X) / self.sigma_X
self.n,self.p=np.shape(self.Xc)
self.Xn2 = (self.Xc ** 2).sum(axis=0)Comme d’habitude on centre et normalise X. On crée aussi Xn2 qui correspond au vecteur $x’=(|x_1|_2^2,\dots,|x_p|_2^2)$
def s_threshold(self,z, a):
return np.sign(z) * max(abs(z) - a, 0.0)
def cd_lasso(self,iter,a,y,b_i,tol):
y = np.asarray(y).reshape(-1)
yc= y - y.mean()
beta = b_i
for i in range(iter):
beta_old= beta.copy()
for j in range(self.p):
x_j=self.Xc[:,j]
r_j=yc-self.Xc@beta+x_j*beta[j]
xr=np.dot(x_j,r_j)
beta[j]=self.s_threshold(xr,a)/self.Xn2[j]
if np.max(np.abs(beta - beta_old)) < tol: #critère avec norme inf pour pas faire d'iter inutile
break
return beta #,y.mean()-X.mean(axis=0)@betaIci, on a omis l’intercept, car le lasso n’agit pas dessus.
La fonction s_threshold donne la valeur optimale de $\beta_j$ comme vu précédemment (à un facteur multiplicatif près).
cd_lasso correspond à l’algorithme de coordinate descent, on voit bien qu’on actualise cycliquement les $\beta_j$ en fonction de l’itération précédente.
On utilise ici un critère avec la norme inf de $\beta$ pour ne pas faire d’itération inutile. De plus, le chemin des solutions de lasso est continue et par conséquent au lieu de restart à chaque fois avec la même initialisation (par exemple $\beta=0$), on prend comme $\beta_{initial}$ le $\beta$ du dernier $a$. Plus précisement, avec $a_k$ et $a_{k+1}$ proche l’un de l’autre, on a $\beta(a_k) \approx \beta(a_{k+1})$.
On termine par le lasso_path qui nous permet de confirmer nos résultats théoriques.
Déjà, il faut choisir une grille de valeurs pour $\lambda$ (dans le code, on utilise a car lambda est un mot réservé en Python).
On sait que pour un $\lambda$ suffisamment grand, la solution du LASSO est nulle. Plus précisément, en notant $y_c = y - \bar y$, on définit :
Alors, pour tout $\lambda \ge \lambda_{\max}$, on obtient $\beta = 0$. Cette valeur correspond à a_max dans le code.
def lasso_path(self,y,iter,tol):
y = np.asarray(y).reshape(-1)
yc= y - y.mean()
a_max = np.max(np.abs(self.Xc.T @ yc))
a_all = a_max * np.logspace(0, np.log10(1e-3), 200)
beta=np.zeros(self.p)
path=[]
for a in a_all:
beta = self.cd_lasso(iter,a,y,beta,tol)
path.append(beta.copy())
return a_all, np.array(path).TEnfin, on récupère les path de chaque coefficient en fonction de log(a/$\lambda$) grâce à cd_lasso.
On a transposé path pour pouvoir l’exploiter correctement.
Voici les résultats pour le dataset california_housing de sklearn: 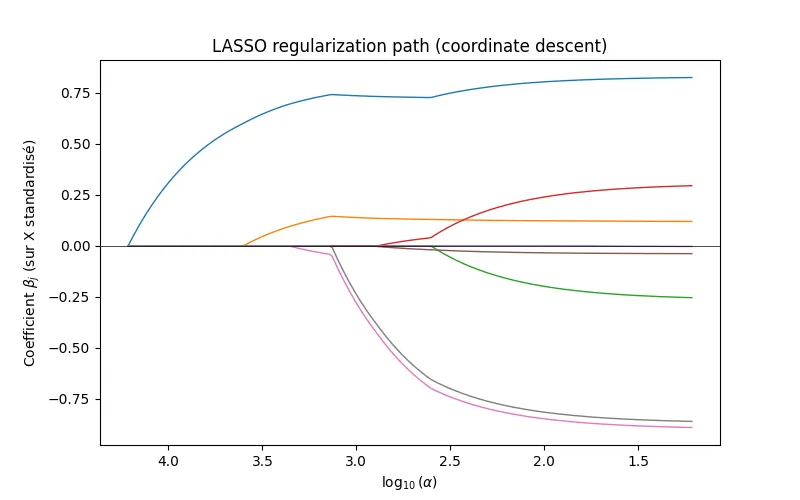
L’axe des abcssies est décroissant et logarithmique! Chaque courbe correspond à un coefficient et on observe bien que chaque courbe ne vont pas en 0 en même temps. Les coefficients valent bien exactement 0 et l’objectif du lasso est réalisé.
Les chemins de régularisation obtenus coïncident avec ceux de sklearn, ce qui valide notre implémentation.
Notre algorithme converge toutefois plus lentement en raison d’une implémentation naïve du coordinate descent.
Le problème étant convexe, les différences observées sont dues uniquement à des considérations numériques.
On rappelle néanmoins que le coordinate descent est une approximation numérique de la solution optimale (un algo comme LARS peut donner la solution “exact”) dépendant de notre critère tol et du conditionnement de X.
ici, on ne s’est pas intéréssé à l’interprétation des résultats, ni à de la prédiction. En pratique, on cherche à choisir le $\lambda$ de sorte à maximiser la prédiction, on utilise majoritairement de la cross-validation et on prend le $\lambda$ qui minimise la loss.